Analyse d'images de bandes dessinées guidée par la connaissance du domaine
Christophe Rigaud, Clément Guérin, Dimosthenis Karatzas, Jean-Christophe Burie, Jean-Marc Ogier
International Journal on Document Analysis and Recognition (IJDAR), 2015
Résumé
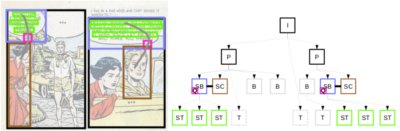
L’analyse de documents est un domaine de recherche actif qui aujourd’hui permet de retrouver la sémantique des documents. Un exemple de compréhension automatisé de documents est de demander à un ordinateur d’identifier les éléments clés de l’histoire d’une bande dessinée puis de les organiser selon la connaissance du domaine (ex. : les cases décrivent des scènes successives, les scènes sont composées de bulles et de personnages inter-agissants). Dans cette étude, nous proposons un système capable de combiner de l’information dite « bottom-up » et « top-down » afin de retrouver le contenu et la sémantique du document. Nous modélisons les domaines de la bande dessinée et du traitement d’image dans le but d’assurer la cohérence et consistance des informations ainsi retrouvées. En outre, différentes méthodes de traitement d’image sont améliorées ou développées pour extraire les cases, les bulles, les queues, le texte, les personnages et leurs relations sémantiques de manière non supervisée. (traduction de l'anglais)
Citation BibTeX
@article{
title={Knowledge-driven understanding of images in comic books},
author={Rigaud, Christophe and Gu{'e}rin, Cl{'e}ment and Karatzas, Dimosthenis and Burie, Jean-Christophe and Ogier, Jean-Marc},
issn={1433-2833},
journal={International Journal on Document Analysis and Recognition (IJDAR)},
doi={10.1007/s10032-015-0243-1},
url={http://dx.doi.org/10.1007/s10032-015-0243-1},
publisher={Springer Berlin Heidelberg},
pages={1-23},
year={2015}
}